
hwchung 님의 블로그
[Paper Review] ICLR 2023, Flow Matching for Generative Modeling 논문리뷰 본문
[Paper Review] ICLR 2023, Flow Matching for Generative Modeling 논문리뷰
hwchung 2026. 1. 26. 14:16Flow Matching for Generative Modeling
ICLR 2023
0. 핵심
어떤 data-distribution 에서 simple-distribution (e.g. standard gaussian) 으로 변화하는 path (e.g. forward-diffusion process) 를 좀 더 잘 정의해서, 그것의 inverse (image generation via the diffusion model) 또한 더 잘 되도록 하고싶다가 핵심.

노이즈를 더해가는 방식 비교
(Top) Diffusion forward process
(Middle) Diffusion Flow-matching
(Bottom) Optimal transport flow-matching
Diffusion의 경우에는 매 step 마다 더해지는 노이즈가 random한 형태로 노이즈가 더해짐. 반면, flow-matching에서는 image에서 noise로의 변환이 매끄럽게 이어짐. 어떤 noise로 이동할지 정해놓고, raw-image에서 해당 noise로 이동하는 것임.
Diffusion vs Flow matching
Diffusion에서는, forward-diffusion에서 timestep 하나하나마다 stochastic한 어떤한 값이 더해짐. 즉, 매 timestep마다 randomness가 있다고 할 수 있음(매 step마다 더해지는 noise가 다름).
Diffusion model들은 복잡한 데이터의 분포에서 정규분포로 변환하고, 다시 반대로 복잡한 데이터의 분포로 변환하는 과정을 거침. 다소 제한적인 이동 방식 때문에 데이터 분포의 다양성이나 복합성을 충분히 반영하지 못함. 또한 다양한 경로(time step)를 통과하고 변화시켜야하기때문에 훈련 시간이 매우 길어짐.
반면, Flow-based 모델에서는 매 timestep마다 deterministic하게 이동함. 즉, 어떤 데이터에 대해 단 하나의 end-point(probably sampled from the standard gaussian)가 있음(매 step마다 더해지는 noise가 같고, 초기값 x_0이라고 했을 때 항상 동일한 x_1에 도착한다는 말.). (- 더해진다? x → 매 step마다 더해지는 noise 정해져있다.) → 따라서, Diffusion(SDE modeling) 과 달리, Flow-matching(ODE modeling; no stochastic term) 하에서 이미지를 생성하고 싶다고 할 때, 처음 pure-gaussian noise를 결정하고나면, 해당 x0 로 부터 이미지로 가는 path는 deterministic하다고 할 수 있음. - ddim, ode 이미지를 생성하는 과정에 random?

위와 같은 flow-matching의 deterministic한 매커니즘을 기술하는 formulation으로 normalizing flow를 사용함. Normalizing flow는, 확률분포를 계속 더 단순한 분포로 변경해나가는 좀 더 일반화된 과정임(forward-diffusion과 유사.). 이후 그것을 거꾸로 변환시켜 나감(backward-diffusion과 유사.). → 논문에서는 flow와 관련하여 직접적으로 구현할 수는 없다고 말함. x_0에서 시작한 데이터에 대해서 확률분포가 변해가는 것에 대해서 무엇으로 정의하고 inverse는 어떻게 구하는 것에 대해서 명확하게 알 수는 없음. 이유는 (1) 진짜 optimal flow를 알 방법이 없음, (2) Jacobian 계산 어려움, (3) high-dim에서 unstable (4) 데이터 manifold 복잡. 따라서 이것을 tractable 하게 구할수 있는 setting을 논문에서 고안함.
1. Background
flow-matching의 formulation에 사용되는 normalizing flow와, 확률변수의 변환에 대해서 간단하게나마 설명.
(Normalizing) flow
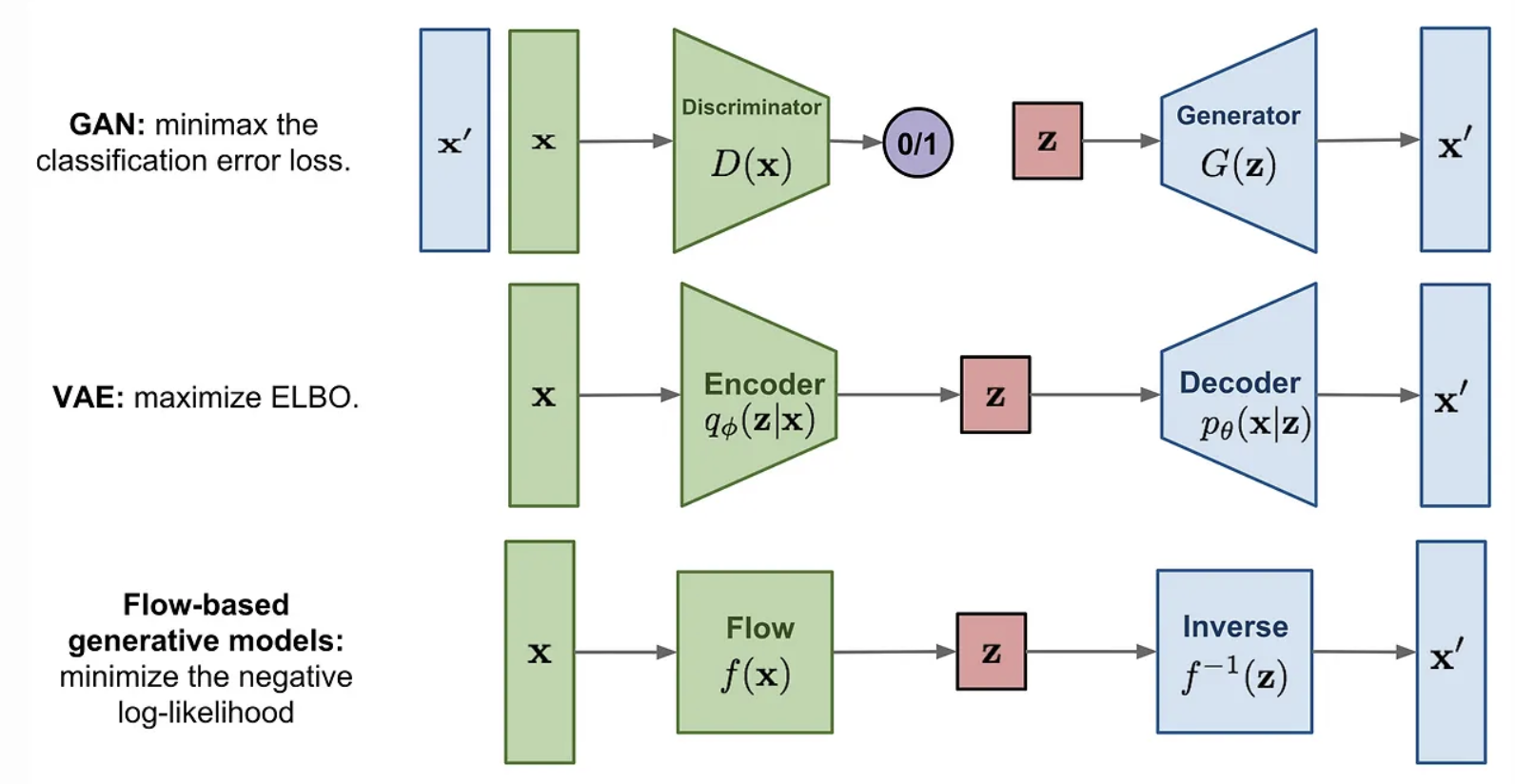
Normalizing flow 의 목적은, 어떤 쉬운 분포(gaussian) z와 데이터 x 사이를 invertible한 변환 f(flow)로 연결하여 복잡한 확률분포 p(x)를 모델링하는 것임. Diffusion처럼 noise 과정을 학습하는 것도 아니고 GAN처럼 분포만 맞추는 것도 아니고 뭔가.. 가역적인 생성 변환(flow)을 직접 만듦.
이걸 이용하여 flow matching까지 이해를 해보면, 이상적으로는 존재하지만 직접 알 수 없는 true flow를 조건부 확률 경로에서 계산 가능한 vector field로 대체하여 그와 같은 flow를 만들어내는 방법임.

위의 확률분포의 변환 fi(flow) 를 어떤 분포 pi(zi)에 대해 지속적으로 해주는 어떤 모델을 설계함. 여기서, f를 디자인할때, f는 역함수가 존재하는 어떤 연산이어야 함(flow model의 정의상 거꾸로 되돌릴 수 있어야 하기 때문.).
확률변수에 대한 변환과 change of variables
그래서… Flow matching은 diffusion과 달리 확률변수를 지속적으로, 결정적(deterministic, not randomness)으로 변환시켜 나가는 과정으로 이해하면 됨. 여기서는 그러한 변환이 어떤식으로 정의되는지를 다룸.
에 대한 확률변수의 변환: X to Y 로의 변환을 한다고 생각해보고 여기서 변환은 어떤 함수 g 에 의해 일어남. Y=g(X). 또한, 함수 g가 invertable(역함수가 존재.)하고 bijective(일대일 대음.)하다면, 해당 변환의 역변환도 정의할 수 있음.
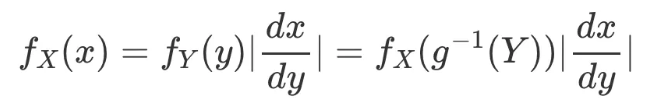
Multi-variate Random Variable 에 대한 변환은 위 dx/dy가 Determinant-of-Jacobian 으로 변한 형태임.
Determinant of Jacobian 의미

확률분포를 X에서 Y로 변경했으면, 확률분포의 정의를 만족하도록(적분 값이 1) 서로 스케일을 맞추라는 뜻. → 해당 스케일을 맞추는것이 위의 determinant임.
이러한 확률변수의 변환을 여러번 하여, 단순한 확률분포를 우리가 원하는 복잡한 분포로 바꾸거나, 거꾸로 복잡한 분포를 단순하게 만들 수 있음. 실제로, 확률변수의 변환을 직접적으로 활용하는 normalizing flow에서는, 확률변수에 대한 변환을 여러개를 구성하고, 그것들의 역변환을 구성함.
constructing the transformation with the vector field
normalizing flow에서, discrete한 형태로 표현되었던 확률분포의 변환들은 본 논문에서는 continuous하게 표현됨. 여기서 discrete하다는 것은 변환이 딱 k번 일어나고, 각 변환은 서로 다른 함수로 이루어짐. 즉… 각 step은 서로 독립적인 함수 f_k로 이루어진다고 보면되고, 결과적으로는 변환이 연속적인 흐름이 아니라, 뚝뚝 끊어진 단계들의 조합이라고 보면 됨. continuous는 다음과 같이 이해하면 됨. 매 timestep t∈[0, 1] 마다 어떤 변환이 있다고 보면 됨. 가령 t=0: 원래 데이터, t=1: 최종 latent 라고 할 때, 변형되는 step k가 있는 것이 아닌, 그 사이 모든 t에서 조금씩 변형된다고 보면 됨. [0,1]에서의 실수는 무한하다고 봐야됨. - continuous 0.99999… input관점
그래서 논문에서는 변형을 vector-field 라는 개념으로 만들어냄. 우선, 위의 normalizing flow에서의 확률변수의 변환 자체를 k개의 고정된 어떤 함수가 아니고 [0, 1] 사이의 연속적인 시간 t 에서 일어난다고 생각해보면,
- probability density path, pt : t 시간에서의 X의 PDF(probability density function).
- flow, ϕt : t 시간에서의 “확률변수 X의 변환.
- time-dependent vector field, vt : t 시간에서의 flow ϕt 를 변화시키는 값 → flow의 시간에 대한 미분(즉 vector field를 알면, 시간에 따라 확률분포를 어떻게 바꾸어 나갈건지 알 수 있고, 따라서 확률분포도 알 수 있음.) → 중간 시점에서 어디로 가야됨? 미분값
- → 조금 더 이해 → vector field는 flow를 만드는 규칙이고, flow는 규칙을 시간에 따라 실제로 적용한 결과라고 이해하면 될듯함… → 그래서 flow_t(x)는 초기값 x가 시간 t까지 흘렀을 때 도착한 위치이고, flow_t(x)를 t에 대해서 미분하면 flow가 시간에 따라 어떻게 변하는지 알 수 있음.
→ 한 공간에 점들이 흩어져있는 것은 distribution이라고 할 수 있고, (vector field)에 따라 움직임. 시간이 지나면 점들이 퍼지거나 휘어질 수 있음. → 점들의 density가 변함. → 점들의 density가 변하는 것이 곧 확률분포가 변한다고 할 수 있음.
probability distribution p_0 와 확률변수 X, 그리고 해당 분포를 구성하는 "particle"(논문에서의 표현.) 이 있다고 가정. 가상의 data-point, particle 들이 무수히 모혀서 p_0를 구성한다고 생각해보면 이 particle들은 0 → 1 로의 timepoint마다([0,1] 무한한 실수 t) vector field v_t에 의해서 아래 그림처럼 이동함(continuous하게.).


하지만
중간에 변환(flow)이 어떻게 생겼는지 모르고, 당연히 그에 상응하는 vector field도 뭔지 모름. 그걸 알면 flow matching을 쓸 이유가 없음(내 생각).
일단, 시간t에서, 특정 데이터 x 에 대한 vector field v_t(x) 를 안다고 가정했을 때, 해당 v_t(x) 에 대한 regression task를 정의해보면, 이게 바로 flow-matching model 에서의 training objective가 될 것임. 즉 학습을 해야할 task가 됨. 다만, true vector field에 대해서 알 수 없기에(t=0에서의 분포에서 t=1에서의 분포 중간에 있는 분포를 모르기 때문에 중간에 있는 분포에 대한 정확한 vector field도 모름.) conditional probability path 라는 것을 정의해서 무언가 tractable한 v_t를 정의하고자 함.
Conditional probability paths
Conditional probability path, p_t(x|x_k)는 특정 데이터 샘플 x_k 에 대해서, 아래와 같은 성질을 만족함. 즉, 시간 t에서의 확률분포인데, 특정 샘플 x_k가 주어졌다는 조건 하에서의 분포.
- p_0(x|x_k) = p(x) → 조건 x_k를 걸었지만, 분포는 조건을 전혀 걸지 않은 것과 동일함. 즉 시작할 때는 어느 데이터로 갈 지 모른다는 것임. 모든 conditional path가 같은 출발선에서 시작한다는 말. 보통은 p(x)는 standard gaussian임.
- p_1(x|x_k) to be a distribution concentrated around x=x_k → t=1이 되면 분포가 특정 데이터 x_k 주변으로 몰려야 함.
이해
각 데이터 샘플 x_k마다, 시간 0에서는 모두 같은 시작 분포에서 출발해서, 시간 1에서는 그 샘플 근처로 수렴하는 하나의 전용 확률 경로 를 정의한다고 이해하면 될듯. 그 전용 확률 경로에서 이 위치의 점은 어디로 이동해라 라고 하는 것이 vector field.

Flow-matching은 각 데이터 샘플 x_k에 대한 조건부 이동 규칙(conditional path)을 먼저 정의하고, 고정된 시간 t와 위치 x에서 가능한 모든 목적지 x_k에 대한 조건부 이동 방향을 평균내어, 시간, 공간 전체(x,t)에서 정의된 하나의 vector field를 구성하는 방법.
이해
각 데이터 샘플 x_k에 대한 조건부 이동 규칙을 정의한다?
→ 데이터셋에 샘플이 많음: x_1, x_2, … , x_k → flow Matching은 처음부터 전체 분포를 한 번에 움직이려 하지 않음. 대신 샘플 하나 x_k만 목표라고 가정하면, 노이즈에서 이 샘플로 가는 길은 정의할 수 있지 않나을까? 그래서 각 x_k마다 같은 base distribution(보통 standard Gaussian)에서 시작해서, x_k 근처까지, 그리고 중간은 당연히 t, [0,1] 시간에 따른 분포겠지…?
그리고 나면, 특정 샘플 x_k, 특정 시간 t_? 에서 분포가 변하려면 어느 방향으로 움직여야 하는지를 알아야 함. → 조건부 vector field.
하지만, 하나의 점(particle)이 시간 t에서 특정 위치 x에 있다고 했을 때, 이 점이 어떤 하나의 데이터 샘플 x_k 로 확정적으로 이동한다고 말할 수는 없음. → 목적지가 unique하게 정해져 있지 않다고 봐야함. 따라서 여러 데이터 샘플 x_k들에 대해 확률적으로 열려(open) 있는 상태.
따라서 시간 t와 위치 x를 고정했을 때, 이 점이 각 데이터 샘플 x_k로 이동하게 될 가능성(확률) 이 존재하고, 각 x_k를 목적지로 가정했을 때의 이동 방향 역시 서로 다를 수 있음. Flow Matching의 입장에서는 지금 이 위치의 점은 평균적으로 어느 방향으로 움직이는 것이 맞음?에 대한 의문을 제기..
이를 해결하기 위해 가능한 모든 목적지 x_k에 대해 각 목적지를 목표로 했을 때의 조건부 이동 방향(conditional vector field)을 그 목적지가 될 확률만큼 가중 평균한다.
이동 방향을 어떻게 정의하느냐는 선택은 조건부 확률 경로를 어떻게 설계하는지에 따라 달라질 수 있음.
논문에서는 Diffusion path도 설명하지만 diffusion path를 선택하면 노이즈를 점진적으로 섞고 제거하는 확률 경로가 정의되고, 그 경로로부터 곡선(curved) 형태의 조건부 이동 방향이 유도된다고 말함.
또한, Optimal Transport(OT)path를 선택하면 노이즈에서 데이터까지 직선에 가까운 확률 경로가 정의되고, 더 단순하고 일관된 조건부 이동 방향이 유도됨. 이렇게 조건부 확률 경로를 정의하는 방식이 조금씩 다르지만, 어쨌든 각 선택으로부터 계산된 조건부 이동 방향들을 평균낸 결과가 바로 전역(marginal) vector field가 됨.
→ 시간 t, 위치 x에 있는 입자는 평균적으로 어디로 가야 함?
→ 시간 t 를 하나 고정함.
→ 그 시간에서 공간의 한 위치 x를 봄.
→ 그 위치에 있는 입자가 어떤 데이터 x_k 로 가게 될 가능성이 있는지를 봄.
→ 각 목적지 x_k에 대해 그 목적지로 간다고 가정하면 지금 x에서 어느 방향으로 움직여야 하는가?를 계산.
→ 그 방향들을 목적지 x_k가 될 확률만큼 가중 평균.
→ 그 평균 방향이 시간 t, 위치 x에서의 vector field임.
Loss
Conditional flow를 맞추는 loss를 사용하면, 우리가 원래 맞추고 싶었지만 정의도 계산도 불가능했던 true flow에 대한 loss와 기댓값 수준에서 동일한 gradient를 가짐.
conditional path에서 그 path에서 유도되는 조건부 vector field는 계산 가능. 그래서 이걸 MSE 회귀로 맞춤.