
hwchung 님의 블로그
[Paper Review] ICML 2015, Deep Unsupervised Learning usingNonequilibrium Thermodynamics 논문리뷰 본문
[Paper Review] ICML 2015, Deep Unsupervised Learning usingNonequilibrium Thermodynamics 논문리뷰
hwchung 2026. 2. 6. 17:13Deep Unsupervised Learning usingNonequilibrium Thermodynamics
ICML 2015
- 논문 링크: https://arxiv.org/abs/1503.03585
- github 링크: https://github.com/Sohl-Dickstein/Diffusion-Probabilistic-Models
0. Abstract
먼저, 2015년 논문을 들고온 이유는 DDPM(Denoising Diffusion Probabilistic Models)의 근간이 되는 논문이기 때문임. 실제로 DDPM 저자들도 'Deep Unsupervised Learning usingNonequilibrium Thermodynamics' 논문을 토대로 전개한다고 언급하기도 함. 따라서 DDPM을 명확하게 이해하기 위해서는 해당 논문에 대해서 어느 정도 이해하고 넘어가야 한다고 생각하여 간단하게나마 paper review를 준비하였음.
problem task는 다음과 같음. Machine learning에서 data는 엄청 복잡함. model을 유연하게 만들면 계산이 어려워지고 계산을 쉽게 만들면 표현력이 떨어짐. 이걸 논문에서는 다음과 같이 표현함. Historically, probabilistic models suffer from a tradeoff between two conflicting objectives: tractability and flexibility. Models that are tractable can be analytically evaluated and easily fit to data.
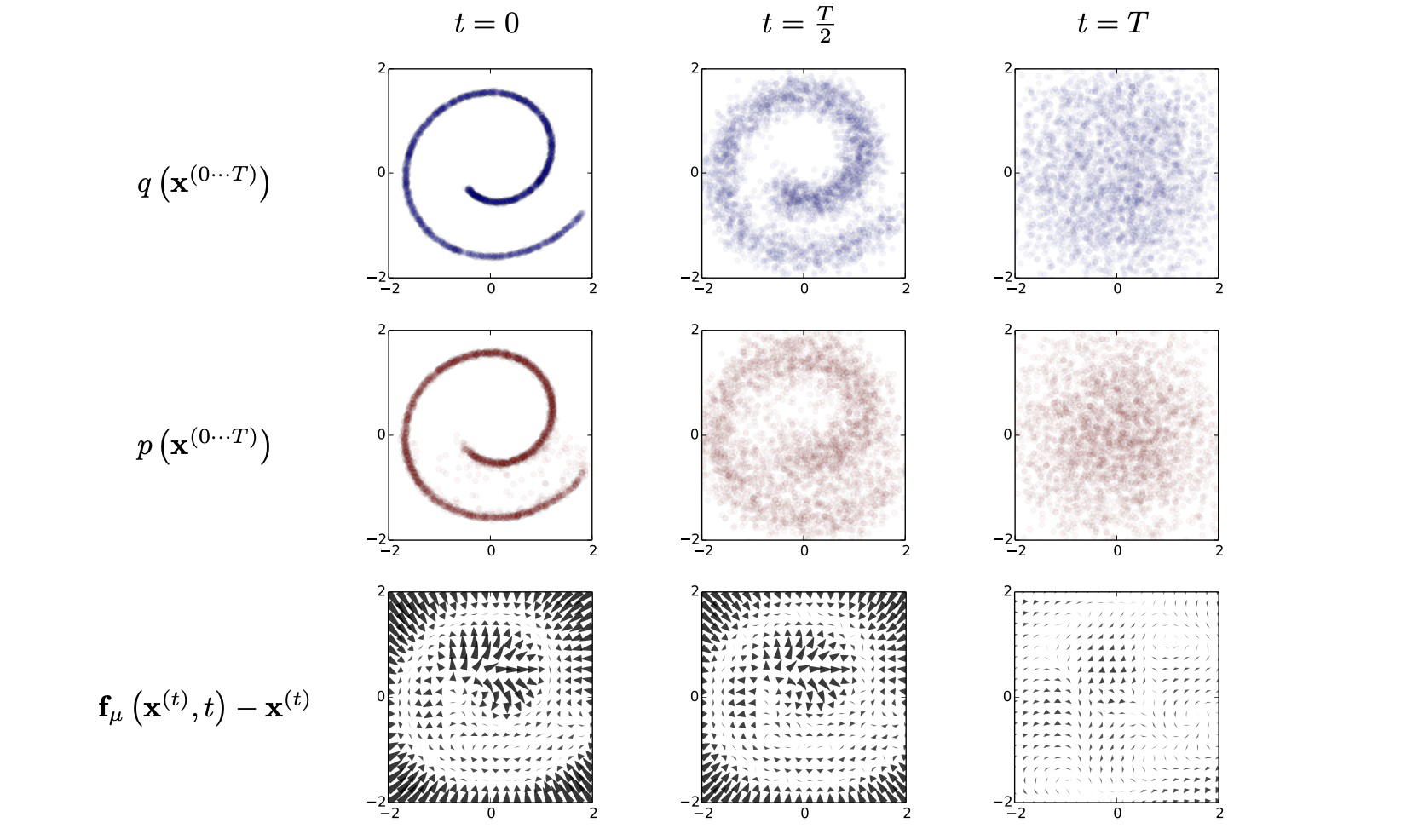
이를 해결하기 위해서 diffusion을 제안함. 데이터를 조금씩 망가뜨려가며 완전한 noise가 되도록 확률적으로 진행함(Forward diffusion). 그 다음, 그 반대 과정을 학습함. Noise에서 시작해서 원래 데이터로 복원하는 과정을 학습함(Reverse Diffusion).
결과적으로 noise → 이미지(데이터)를 잘 만들어냄. 계산도 가능하고, 샘플링도 빠르고, 확률 계산도 됨. 층이 수천 개여도 학습 가능함.
1. Introduction
생성 모델은 일반적으로 tractability와 flexibility 사이의 trade-off를 가짐. Gaussian 분포와 같은 tractable한 모델은 확률 계산, 학습, 샘플링이 수치적으로 가능하다는 장점이 있음. 다만, 실제 이미지와 같은 고차원 복잡 데이터의 분포를 충분히 표현하기 어려움.
한편, Boltzmann machine이나 일반적인 energy-based model과 같이 높은 표현력을 가진 모델은 복잡한 데이터 분포를 기술할 수 있으나, 학습 및 추론 과정에서 Monte Carlo sampling에 의존해야 하며 계산 비용이 크고 수렴이 불안정함.
본 논문은 이러한 문제를 해결하기 위해 유연성과 계산 가능성을 동시에 만족하는 새로운 확률적 생성 모델의 구성 방법을 제안함. 저자들은 다음 네 가지 조건을 만족하는 생성 모델을 목표로 한다.
- 임의의 데이터 분포를 표현할 수 있는 높은 flexibility
- 정확한 샘플링이 가능한 명시적 확률 모델
- 다른 확률 분포와의 결합을 통한 조건부 확률 및 사후 확률 계산 가능성
- 모델의 log-likelihood 및 각 상태의 확률을 수치적으로 계산 가능함
Diffusion Process를 이용한 Generative Markov Chain
저자들은 생성 모델을 diffusion process에 기반한 Markov chain으로 정의함. Forward diffusion 과정에서는 원본 데이터 분포 p_data(x_0)에서 시작해서, 각 단계마다 작은 Gaussian noise를 추가함으로써 데이터의 구조를 점진적으로 파괴함. 충분히 많은 step 이후에는 분포가 단순한 Gaussian 분포로 수렴하게 됨. 이 과정은 다음과 같은 Markov chain으로 표현된다.
x_0 → x_1 → x_2 → ... → x_t
각 단계는 Markov property를 만족하고, x_t는 오직 이전 상태 x_{t-1}에만 의존함. 또한 각 transition probability(probability of x_t, given x_{t-1})는 Gaussian 분포로 명확하게 정의되므로, 전체 forward diffusion chain의 확률은 수치적으로 tractable함.
Reverse Diffusion Process의 학습
생성 모델의 핵심은 forward diffusion의 역과정(reverse process)을 학습하는 데 있음. Forward diffusion 과정은 사전에 정의되어 있으며 학습 대상이 아님. 대신, 모델은 다음과 같은 역방향 transition을 근사함. probability_theta of x_{t-1}, given x_t. 이 과정은 노이즈 상태에서 점진적으로 데이터 구조를 복원하는 과정이고, 각 단계에서의 변화는 매우 작고 국소적임. 이러한 작은 변화들을 신경망으로 모델링함으로써, 전체 데이터 분포를 암묵적으로 학습할 수 있음.
작은 변화 학습의 장점과 Tractability
기존 energy-based model은 하나의 전역적인 potential function을 통해 데이터 분포를 정의하고, 이로 인해 정규화 상수 계산이 불가능하거나 매우 어려움. 결과적으로 학습과 샘플링 과정에서 MCMC(Markov Chain Monte Carlo)가 필수적으로 요구됨.
반면, 본 논문에서 제안하는 diffusion 기반 접근법은 전체 분포를 직접 모델링하지 않고, 연속적인 시간 축에서의 국소적인 확률 변화만을 학습함. 각 step에서의 변화는 거의 Gaussian perturbation에 가까우므로 학습이 안정적이며 수치적으로 tractable함. 이러한 구성은 복잡한 분포를 여러 개의 단순한 변환으로 분해하여 학습하는 효과를 가짐.
표현력에 대한 보장
저자들은 임의의 데이터 분포에 대해 forward diffusion process가 항상 정의될 수 있음을 보이고, 대응하는 reverse process 역시 존재함을 논의함. 이는 제안된 모델이 특정 분포 가정에 제한되지 않고, 이론적으로 임의의 데이터 분포를 표현할 수 있는 충분한 유연성을 갖는다는 것을 의미함.
2. Algorithm
데이터 분포를 $q(x^{(0)})$, tractable한 간단한 분포를 $\pi(y)$, $\pi(y)$에 대한 Markov diffusion kernel을 $T_\pi(y\mid y')$,
diffusion rate를 $\beta$라 하면 다음과 같음.
- $q(x^{(0)})$: 관측된 데이터가 따르는 실제 데이터 분포
- $\pi(y)$: tractable한 기준 분포(reference distribution), 일반적으로 표준 Gaussian 분포
- $T_\pi(y\mid y')$: 분포 $\pi$를 stationary distribution으로 갖는 Markov diffusion kernel
- $\beta$: diffusion rate, 각 단계에서 추가되는 노이즈의 크기를 조절하는 파라미터
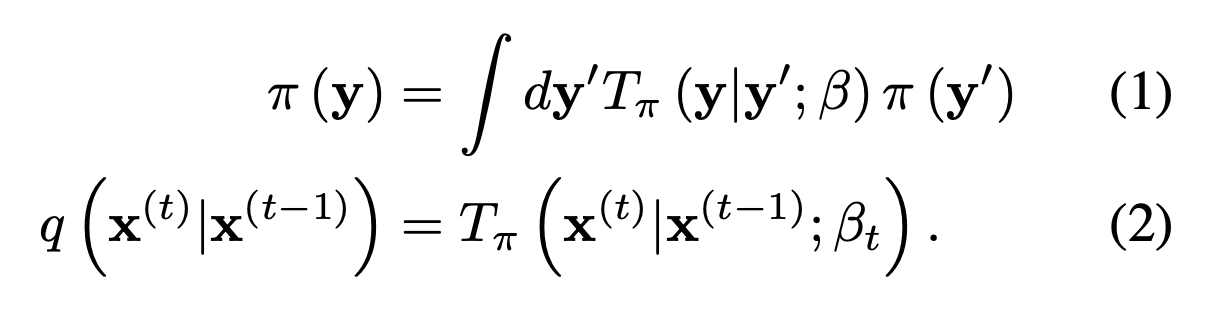
여기까지만 정리하고 ddpm에서 수식 전개 등은 따로 정리할 예정.