
hwchung 님의 블로그
[Paper Review] ICLR 2021, AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문리뷰 본문
[Paper Review] ICLR 2021, AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE 논문리뷰
hwchung 2026. 2. 25. 16:15AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
ICLR 2021
- 논문 링크: https://arxiv.org/abs/2010.11929
- github 링크: https://github.com/google-research/vision_transformer
0. Abstract
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited.
In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place.
1. Introduction
Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications.
To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion.
When trained on mid-sized datasets such as ImageNet without strong regularization, these models yield modest accuracies of a few percentage points below ResNets of comparable size. → ImageNet같은 중간 크기의 데이터에서는 regulation 없이는 ResNets 보다도 성능이 떨어짐. Translation equivariance(위치가 바뀌어도 같은 특징을 인식하는 특성), locality(가까운 픽셀끼리 먼저 보는 특성)이 없기 때문에 불충분한 크기의 데이터에서는 일반화하기가 쉽지 않음.
However, the picture changes if the models are trained on larger datasets (14M-300M images). We find that large scale training trumps inductive bias.
Our Vision Transformer (ViT) attains excellent results when pre-trained at sufficient scale and transferred to tasks with fewer datapoints. → 충분히 큰 규모로 pre-trained 시킨 다음에, 데이터가 적은 다른 task로 transfer learning을 적용하면 더욱 뛰어난 성능을 내는 것을 알 수 있음.
2. Related Work
Naive application of self-attention to images would require that each pixel attends to every other pixel. With quadratic cost in the number of pixels, this does not scale to realistic input sizes. Thus, to apply Transformers in the context of image processing, several approximations have been tried in the past. → self-attention을 그대로 image에 적용하게 되면, 계산량이 픽셀의 제곱으로 증가하기 때문에 연산량이 늘어남. 그래서 이전에는 계산량 감소 연구가 꾸준히 되어 왔었음.
Most related to ours is the model of Cordonnier et al. (2020), which extracts patches of size 2 × 2 from the input image and applies full self-attention on top. This model is very similar to ViT, but our work goes further to demonstrate that large scale pre-training makes vanilla transformers competitive with (or even better than) state-of-the-art CNNs. Moreover, Cordonnier et al. (2020) use a small patch size of 2 × 2 pixels, which makes the model applicable only to small-resolution images, while we handle medium-resolution images as well. → 논문에서 vision transformer랑 가장 관련이 있다고 말하는 모델은 이미지를 2×2 픽셀 패치 단위로 나눈 뒤에, 그 위에 full self-attention을 적용함.
Kolesnikov et al. (2020); Djolonga et al. (2020) perform an empirical exploration of CNN transfer learning from large scale datasets such as ImageNet-21k and JFT-300M. We focus on these two latter datasets as well, but train Transformers instead of ResNet-based models used in prior works. → large scale data에서 small scale data로 전이학습을 진행하되, ResNet-based model 대신에 Transformer로 학습함.
3. Method
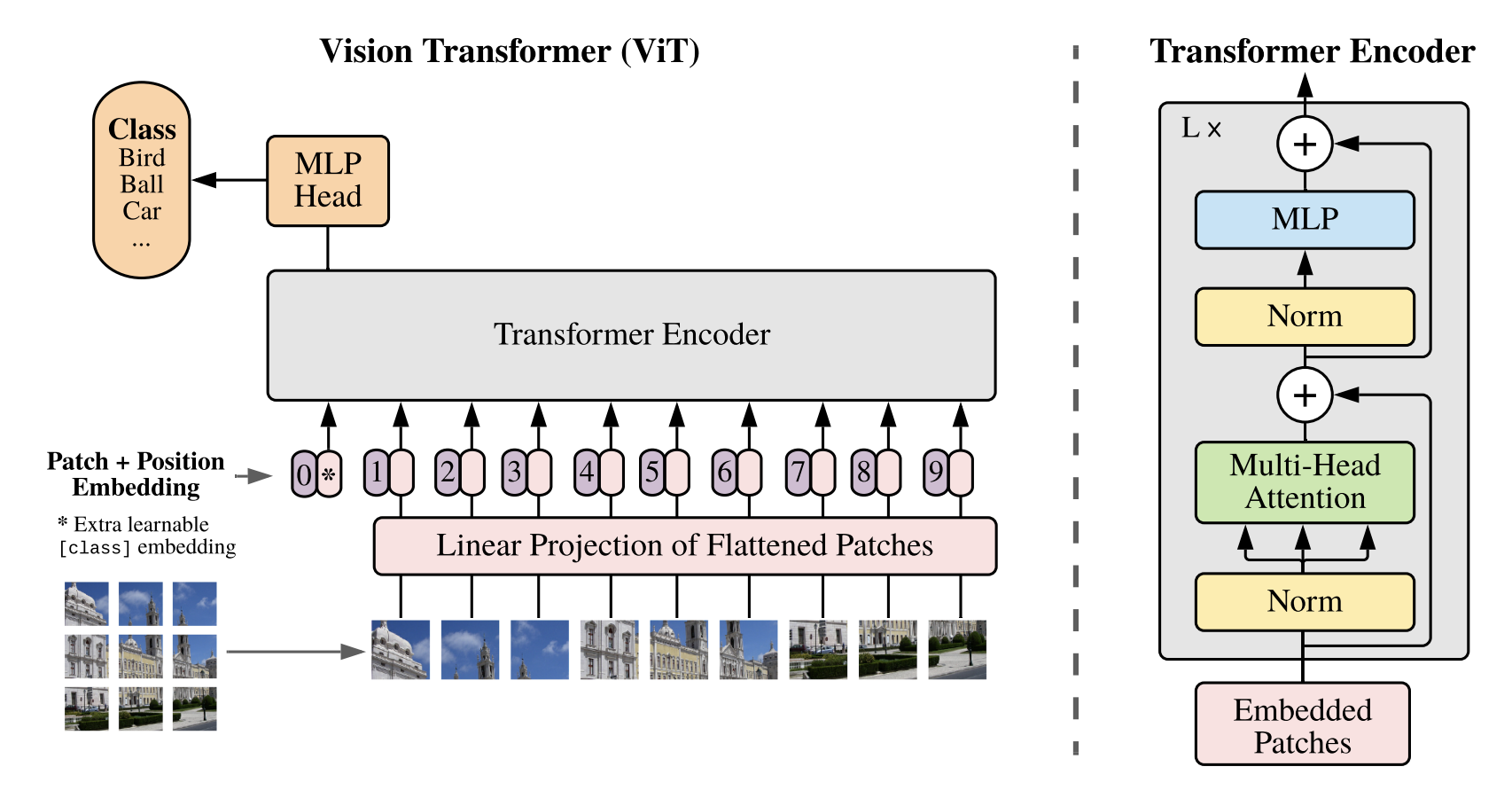
Figure 1: Model overview. We split an image into fixed-size patches, linearly embed each of them, add position embeddings, and feed the resulting sequence of vectors to a standard Transformer encoder. In order to perform classification, we use the standard approach of adding an extra learnable “classification token” to the sequence. The illustration of the Transformer encoder was inspired by Vaswani et al. (2017). → 이미지를 고정된 크기의 작은 패치들로 나누고, 각 패치에 대해 벡터를 생성함. 여기서 position embedding을 추가해서 Transformer model에 입력함. Position embedding을 추가하는 이유는 각 패치가 어떤 위치에 있는지 정보를 제공하기 위함임. 이로 인해서 Transformer 모델이 패치들의 상대적 위치를 이해할 수 있도록 도움을 줌. Classification Token이 조금 이해가 가지 않았는데, classification token을 추가하는 이유는 Transformer 모델에서 이 이미지가 어떤 class(category)에 속하는지를 예측하는 데 사용됨.
기존에 패치 벡터만 사용한다면?
Transformer는 원래 sequence data에서 각 단어를 벡터로 변환하고 이를 처리하여 결과를 도출함. 하지만 이미지는 텍스트와는 다르게 하나의 fix된 sequence가 아니기 때문에, Transformer가 이 이미지를 이해하려면 patch들이 각각 무엇을 의미하는지, 전체적인 이미지를 어떻게 분류할지에 대한 정보가 필요함.
Classification token을 추가하는 이유?
Classification token은 학습할 수 있는 특별한 토큰이라고 이해하면 될듯함. Classification token은 모든 패치의 정보를 요약하고, 이미지가 어떤 class에 속하는지 예측하는 역할을 함. 토큰은 패치들 앞에 배치되고, 훈련 중에 이 토큰의 값을 통해 이미지의 최종 분류 결과를 도출함. Train 중에는 [CLS] 토큰은 image patch를 통해 class prediction을 위한 정보를 학습함.이미지의 패치들을 통해 클래스 예측을 위한 중요한 정보를 학습함. 예를 들어, 모델이 고양이, 개, 사람을 분류하도록 훈련된 경우, [CLS] 토큰은 훈련을 통해 고양이, 개, 사람의 특징을 학습함. 이 [CLS] 토큰은 훈련이 진행되면서 이미지가 어떤 클래스에 속하는지를 예측할 수 있는 정보를 점진적으로 학습함.
새로운 이미지를 예측할 때, [CLS] 토큰은 패치들과 함께 Transformer 모델에 입력됨. 모델은 훈련 중에 학습한 [CLS] 토큰을 사용하여 새로운 이미지가 고양이, 개, 사람 중 어떤 클래스에 속하는지를 예측함. [CLS] 토큰은 이제 이미 학습된 값을 바탕으로 새로운 이미지에 대한 예측을 한다고 이해하면 됨.
Method

Method 설명을 하자면 다음과 같음. 중요한 부분이기 때문에, method 부분 논문 전체를 캡쳐하였음(하하..).
Transformer는 기본적으로 1D sequence 형태의 토큰 임베딩을 입력으로 받는 모델임. 즉, Transformer는 원래 단어의 시퀀스를 처리하는데 사용되고, 단어를 벡터로 변환한 임베딩을 입력으로 받음. 그래서 Transformer를 이용하여 vision task를 활용하려면 그에 맞게 image shape도 바꿔주어야 함. 그래서 2D image를 1D sequence로 변환해야 함. 그래서 image에 대해서 patch로 나누고, 각 patch를 vector로 변환하여 Transformer에 입력해야 함.
알고리즘 흐름은, original input image x가 있다고 했을 때, 이미지 x ∈ ℝ^(H×W×C)는 크기 H×W의 해상도와 C 채널을 갖는데, 여기서 이미지는 P×P 크기의 patchs로 나누어 짐. 각 패치는 P²×C 차원의 벡터로 변환됨. 논문에서도 sequence of flattened 2D patches로 언급함. 그렇게 되면, 전체 패치의 수 N = HW/P²로 계산됨. 즉 P×P 크기로 image들이 잘라졌으니까 이 패치들은 1D sequence로 변환되어서 Transformer에 입력이 되는 것임.
그리고 각 patch vector는 D 차원으로 변환됨. Transformer model은 D 차원의 벡터를 고정된 크기로 처리하기 때문에 patch embedding을 D 차원으로 변환해야 함. 그래서 각 patch x_p를 D차원 벡터로 변환하기 위해서 선형 변환을 사용함. 선형 변환은 학습 가능한 매개변수인 가중치 행렬 W를 통해 이루어짐. 수식으로는 x_p → W⋅x_p + b 형태로, 이 변환은 훈련 중에 학습됨. 각 패치가 D 임베딩으로 변환된 후, 패치 임베딩이 됨. 이 패치 임베딩이 Transformer 인코더에 전달이 됨.
또한, BERT의 class token처럼, Vision Transformer에서도 [CLS] 토큰을 패치 임베딩 시퀀스 앞에 추가함. 이 [CLS] 토큰은 학습 가능한 파라미터이고, 훈련을 통해 이미지를 분류하는 데 필요한 정보를 학습함. Transformer 인코더를 통과한 [CLS] 토큰의 상태가 최종적인 이미지 표현인 y로 사용됨.
[CLS] 토큰을 Transformer 인코더에 입력하고, 그 출력에 classification head(MLP)를 추가하여 이미지를 분류함. Pre-training에서는 대규모 데이터셋을 사용하여 기본적인 분류 작업을 학습하고, fine-tuning에서는 특정 작업에 맞춰 최적화함. 즉 [CLS] token이 pre-training 단계와 fine-tuning 단계에서 모두 쓰임.
그리고 CNN과 비교했을 때, Vision Transformer의 단점을 극복하기 위해 position embedding을 사용하여 각 path의 position information을 공유함. Transformer는 순차적인 위치 정보를 모르기 때문에, 이를 위치 임베딩으로 보완함. 각 패치 임베딩에 위치 정보를 더해 위치 임베딩을 생성함. 이 임베딩을 패치 벡터에 더함으로써, 모델이 패치들 간의 상대적인 위치를 이해할 수 있도록 도울 수 있음. 여기서 2D 위치 임베딩은 실험에서 성능 향상을 크게 보지 못했으므로, 1D 임베딩을 선택하였음.
Inductive bias
Inductive bias는 모델이 학습을 통해 데이터를 일반화할 때 사용하는 선험적 가정임. 예를 들어, CNN은 이미지에 특화된 inductive bias를 내장하고 있어, 이미지의 특정 특성을 잘 처리하는 데 유리함. ViT는 이미지의 특성보다는 더 일반적인 Transformer 구조를 사용하여 이미지를 처리함. 또한, ViT는 image-specific한 inductive bias가 CNN에 비해 훨씬 적음. ViT 모델은 CNN에 비해 이미지의 공간적 특성을 강제로 학습해야 한다는 점에서 더 적은 inductive bias를 가진다고 말할 수 있음.
Typically, we pre-train ViT on large datasets, and fine-tune to (smaller) downstream tasks. For this, we remove the pre-trained prediction head and attach a zero-initialized D × K feedforward layer, where K is the number of downstream classes. It is often beneficial to fine-tune at higher resolution than pre-training (Touvron et al., 2019; Kolesnikov et al., 2020).
The Vision Transformer can handle arbitrary sequence lengths (up to memory constraints), however, the pre-trained position embeddings may no longer be meaningful.→ pre-trained position embeddings은 의미가 없을 수도 있음. 원본 훈련 이미지의 해상도와 새로운 입력 이미지의 해상도가 다를 때, position embedding이 의미가 사라질 수 있음.
We therefore perform 2D interpolation of the pre-trained position embeddings, according to their location in the original image. → 그렇기에 pre-trained position embeddings을 2D 보간법(interpolation)을 사용해 새로운 이미지의 해상도에 맞게 조정함.
Note that this resolution adjustment and patch extraction are the only points at which an inductive bias about the 2D structure of the images is manually injected into the Visi on Transformer. → 2D 구조에 대한 inductive bias가 ViT 모델에 수동으로 주입되는 유일한 지점이 해상도 조정과패치 추출임. ViT 모델은 기본적으로 이미지의 2D 구조에 대한 인코딩을 모델 내부에서 학습해야 함. 하지만 위치 임베딩의 보정 과정과 패치 추출 과정에서만 2D 구조에 대한 inductive bias가 명시적으로 모델에 반영됨.